3일차는 바쁘고, 시간도 없었고, 많이 돌아보고, 정말 많이 반성하는 하루였어요…
3일차는 시간이 흘렀지만 꽤 기억에 남는다… 암튼 정말 정말 많은 생각을 했던 날.
이유는 나중에..
3일차는 Kaggle 대회입니다.
팀당 최대 20회까지 파일을 제출하고 실시간 순위표를 볼 수 있습니다.
Re: 악성 웹사이트를 탐지하는 기계 학습
데이터 전처리 -> 모델링 -> 결과 전달 -> 발표 준비 -> 발표 및 피드백
1. 데이터 전처리
– 중복 행 제거
– 불필요한 열 제거
– 결측치 처리
첫째, 데이터셋 크기는 작았지만 많은 값이 누락되었습니다.
데이터셋이 작아 결측값을 제거하다 보니 데이터셋이 너무 작아지므로 최대한 제거하지 않고 다른 방법을 사용하였다.
누락된 값을 처리하는 방법에는 여러 가지가 있습니다. 싸이킷 런그걸로 쉽게
(특히 숫자형과 범주형을 동시에 사용할 수 있음)
그래요 IterativeImputer를 사용했습니다.
IterativeImputer: 다변수 대치 방법
다른 모든 특징에 대해 라운드 로빈 회귀를 수행하여 nan 값으로 특징을 추정하는 방법입니다.
import sklearn
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
# 결측치 대치
imputer = IterativeImputer(random_state=2023)
imputer.fit(test)
im_test = imputer.transform(test)
im_test
#데이터프레임으로 만들기
test_cols = test.columns
test_last = pd.DataFrame(im_test, columns=test_cols)

데이터 프레임에서 값이 누락된 값으로 채워진 것을 볼 수 있습니다.
2. 단체모임
이 프로젝트에서는 시간 내에 최상의 결과를 얻는 것이 중요하므로 전처리 방법을 팀원들과 잘 공유하는 것이 매우 중요했습니다.
우리 팀은 Mural을 사용하여 Eda, 전처리 방법, 전처리 이유, 기능의 중요성 등을 공유하고 더 나은 결과를 얻는 방법에 대한 의견을 교환했습니다.

3. 모델링
모델할 때 승부욕에 눈이 멀어서 급하게 계속해서 모델링을 하고 파일을 제출했는데….
(1) pycaret-autoML
먼저 모델을 pycaret로 가져오고 대략적인 성능 지표를 확인했습니다.
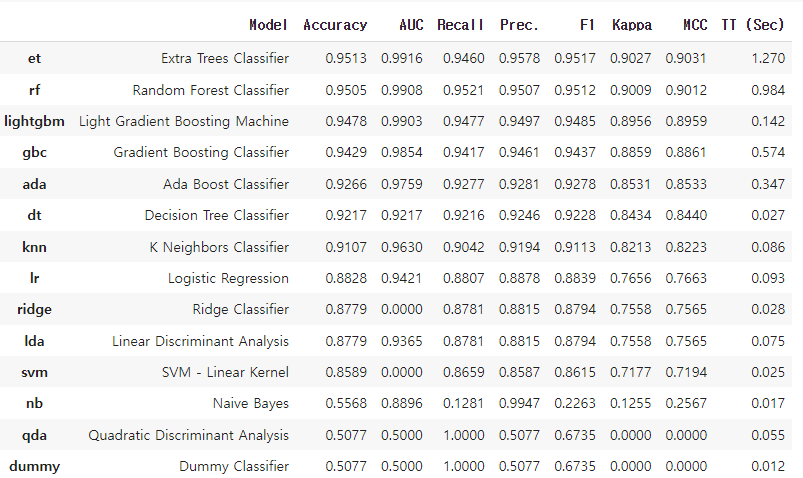
물론 라이브러리를 이용하면 앙상블도 만들 수 있지만 너무 게으른 것 같아서 성능 좋은 모델 3개를 올려봅니다.
(2) RandomForestClassifier 모델링
model = RandomForestClassifier(n_estimators=5, random_state=0)
model.fit(x_train, y_train)
y_pred_rf = model.predict(test)
score = model.score(x_val, y_val)
print("검증 세트 정확도:", score)
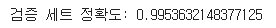
– gridsearchCV최상의 매개 변수를 선택하고 조정하는 데 사용되었습니다.
params ={
'n_estimators':(100),
'max_depth':(6,8,10,12),
'min_samples_leaf':(8,12,18),
'min_samples_split':(8,16,20)}
rf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(x_train,y_train)
print('최적의 하이퍼파라미터:', grid_cv.best_params_)
print('최적의 교차 검증 점수:', grid_cv.best_score_)
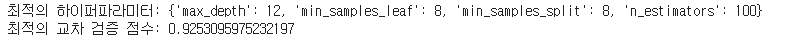
(2) catboost로 모델링하기
model = CatBoostClassifier()
model.fit(x_train,y_train)
# 그리드 탐색 수행
params = {
'depth': (4, 6, 8),
'learning_rate': (0.03, 0.1, 0.3),
'iterations': (100, 500)
}
grid_search = GridSearchCV(model, param_grid=params, cv=3)
grid_search.fit(x_train, y_train)
# 최적의 하이퍼파라미터 출력
print(grid_search.best_params_)
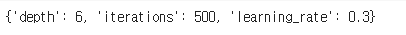
검증 세트 정확도: 0.9598145285935085
(3) lightgbm으로 모델링하기
params = {
'num_leaves': (31, 62, 127),
'learning_rate': (0.01, 0.05, 0.1),
'n_estimators': (50, 100, 200),
'max_depth': (3, 5, 7)
}
# GridSearchCV 모델 생성
grid_cv = GridSearchCV(lgb_model, param_grid=params, cv=3, scoring='f1', verbose=1)
# 학습 데이터로 모델 학습 및 최적 하이퍼파라미터 검색
grid_cv.fit(x_train, y_train)
# 최적 하이퍼파라미터 출력
print('최적 하이퍼파라미터:', grid_cv.best_params_)
# 최적 모델 저장
best_model_gbm = grid_cv.best_estimator_
# 최적 모델로 예측 수행
y_pred = best_model.predict(test)
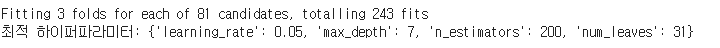
RandomForestClassifier 고양이 부스트 , gridsearchCV를 통해 3개의 Lightgbm 모델의 최적 하이퍼파라미터를 검색하여 각각 저장됩니다. 그리고 예측은 최적의 모델로 이루어졌다.
(4) 앙상블
ensemble_pred = 0.4 * rf_pred + 0.3 * gbm_pred + 0.3 * cat_predrt_pred는 RandomForest의 예측값 확률
cat_pred 고양이 부스트 예측 값의 확률
gbm_pred는 lightgbm의 예측값 확률입니다.
단일 모델에서 RandomForest가 가장 성능이 좋기 때문에 가중치는 0.4를 최대값으로 설정했습니다.
ensemble_pred_binary = np.where(ensemble_pred > 0.5, 1, 0)결과 확률값은 0.5보다 크면 1, 그렇지 않으면 0으로 저장하였다.
4. 결과
13위!!
제출 결과 우리 그룹은 f1 값 0.93936으로 전체 13위를 기록하며 상위 30% 안에 들 수 있었습니다.
다행히도 결과를 발표할 수 있었습니다!!
(아 그리고 프리젠테이션을 했는데.. 프리젠테이션을 하게 될 줄은 생각도 못해서 떨리고 많이 흔들렸네요….)
다른 그룹은 딥 러닝이나 xai를 사용했습니다.
물론 기계학습 프로젝트라 기계학습을 쓸 수밖에 없다고 생각해서 조금은 아쉬웠습니다….
딥 러닝이 가능하다는 것을 알았다면 그렇게했을 것입니다.
5. 인상
서두에 말했듯이 반성을 많이 한 날이었다.
오늘 거의 리드할 뻔 했네요… 중간에 승부욕이 앞을 못 보게 해서 팀원들에게 압박을 가했던 것 같아요…
특히나 손이 빨라서 오전에 모델링을 끝내고… 그래서 다른 팀원들보다 더 많은 파일을 제출할 수 있었습니다…
좋은 결과에 집착해서 결과를 제출하고 반복해서…
그런 행동들이 조금은 민폐가 아니었나 봐요 헤헤…
생각해보니 팀원이 저 때문에 망설이거나 제출을 못 한 건 간과했네요…
팀원들에게 너무 너무 미안하고… 다음에 작품으로 만나면 미안하고 더 좋은 모습 보여드리고 싶어요.